
Building autoscaling CI infrastructure with Azure Kubernetes
Ever wanted to create a build agent factory where you do not have to care about how many build agents you need at a given point?
With this post I want to share my experience setting up a dedicated CI runner infrastructure with the Azure + Pipelines ecosystem.
The main features of the solution are automated scaling, ephemeral build agents, docker based environments, minimal operation responsible and strong pay-per-use billing concepts.
Basic knowledge of Docker and Kubernetes should exists - you should know what they are.
In a previous blog post Migrating to Azure Pipelines I gave an introduction to the Azure CI/CD service from a user perspective. This time I will focus on operational aspects when using Azure Pipelines.
Why build auto scaling CI infrastructure
You might ask Why do you want to build a custom solution for auto-scaling CI infrastructure? There is already X out there.
The easy answer: To learn how things work
The real answer: I could not find a CI system that fulfills all my requirements. What I need the CI infrastructure to be capable of:
- provide real pay per use
- support Linux and Windows agents
- run on specific VMs with special hardware requirements (CPU, GPU, Memory, disks)
- share specific volumes between all runners e.g. cache files
- scale up to 20+ of agents
- everything as code
- state of the art UI with active directory authentication
- scale down to as little agents as possible to reduce costs
- minimal responsibility; as little code and operational efforts as possible
The black box solution
With the goal of not managing everything myself I chose Azure Pipelines as CI environment. It also supports the requirements 1-4 by running arbitrary bash scripts within a pipeline as described in my previous post.
Given the list of requirements the solution can be described with the following picture.
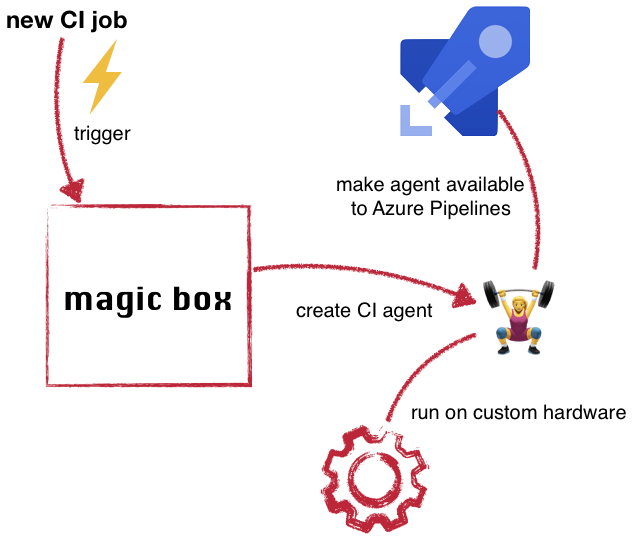
With Azure Pipelines as the CI system in place the open variables are knowing how many agents to host, manage their lifecycle and how to host them.
Hosting the build agent
There are two ways to host your own agents for Azure Pipelines. One is getting the client code and put it on your virtual machine which is described in “Self-hosted Linux agents” article in the azure documentation. The alternative is running it within a docker container. I decided to run the agent in a docker container because having docker as the only dependency on the host offers a wider solution space. The Dockerfile below is taken from the Azure docs.
Dockerfile for Azure Pipelines agent
FROM ubuntu:16.04
# To make it easier for build and release pipelines to run apt-get,
# configure apt to not require confirmation (assume the -y argument by default)
ENV DEBIAN_FRONTEND=noninteractive
ENV DOCKER_VERSION="18.03.1-ce"
RUN echo "APT::Get::Assume-Yes \"true\";" > /etc/apt/apt.conf.d/90assumeyes
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
ca-certificates \
curl \
jq \
git \
iputils-ping \
libcurl3 \
libicu55 \
libunwind8 \
netcat
# add docker CLI
RUN curl -fsSL https://download.docker.com/linux/static/stable/x86_64/docker-$DOCKER_VERSION.tgz | \
tar zxvf - --strip 1 -C /usr/bin docker/docker
WORKDIR /azp
COPY ./start.sh ./start-once.sh ./
RUN chmod +x start.sh start-once.sh
To actually run this dockerized build agent there are multiple options available on Azure.
Docker host options
| Solution | Description | Challenge | Advantage |
|---|---|---|---|
| Virtual Machine | Using a simple virtual machine with the docker engine installed agents can be started | Scaling the VMs up and down; operational effort | very simple solution |
| Virtual Machine Scale Set (VMSS) | VMSS allows creating multiple identical machines via an easy API e.g. count=4 | when scaling down, Azure might pick a VM that is still actively running an agent/job | solves the scaling issue that VMs have |
| Azure Kubernetes Service (AKS) | a managed Kubernetes environment for running docker containers | need to orchestrate agent in Kubernetes | little operation responsibility and full control over hardware spec |
| Azure WebApp for Containers | run docker containers on a previously specified VM type without interacting with the VM directly | same as VMSS | abstracts VM and thereby reduces operational responsibility |
| Azure Container Instances (ACI) | run a docker container inside a fully managed docker environment | does not allow to specify VM type (only CPU count) | least operational responsibility |
Cluster Autoscaler
I chose to run on Azure Kubernetes Service (AKS) because using the right configuration it allows me to implement the pay per use and scalability almost out of the box. The key feature to achieve this is Cluster Autoscaler. Using Virtual Machine Scale Sets (VMSS) for the Kubernetes nodes this feature checks if there are enough resources in the cluster to host all pods.
- 📌 NOTE
A pod in Kubernetes is a group of Docker containers that are run together on the same host
If necessary the cluster autoscaler adds additional virtual machines to the Kubernetes cluster or removes them if they are idle for too long (~10minutes). In the following scenario each build agent is run in a separate pod. Each pod occupies so many resources as a single VM can provide. Thus if a new build agent is needed, one new VM will be needed.
Components involved in the Cluster Autoscaler
How the cluster autoscaler works
Another reason I chose the AKS solution is the fact that I am a bit familiar with Kubernetes and Helm charts as ways of describing the system in code. With automation being another high level requirement I was worried that container instances and web apps might be a bit difficult to orchestrate throughout their lifecycle. Using AKS as a runtime for the agent fulfills the following requirements:
- ✅ provide real pay per use where idle time is reduced
- ⚠️ support Linux and Windows agents: Would require a separate node pool running Windows nodes
- ✅ run on specific VMs with special hardware requirements (CPU, GPU, disks)
- ⚠️ share specific volumes between all runners e.g. cache files: depending on the Helm configuration this is possible
- ✅ scale up to 20+ of agents
- ✅ everything as code
- ✅ state of the art UI with active directory authentication: achieved by choosing Azure Pipelines as CI orchestrator
- ✅ scale down to as little agents as possible to reduce costs
- ✅ minimal responsibility; as little code and operational efforts as possible
📌 NOTE
The exact implementation in Kubernetes will be part of a follow-up blog post
Identifying agent demand
To know how many build agents need to be running in the cluster we need to get information from Azure Pipelines about the number of active jobs.
Active is defined as:
INFO: active jobs = running jobs (already using an agent) + pending jobs (waiting for an agent to be assigned)
Sadly there are no webhooks available in Azure Pipelines that trigger when a new build job is being started. That is why I resorted to polling the Azure Pipelines API to get information about the build status. This can either be done with the HTTP API directly or using the Azure CLI. After installing the Azure CLI, an additional extension is needed to work with the Azure Pipelines (Azure DevOps) API.
az extension add --name azure-devops
The Azure Pipelines API is RESTful and therefore you need to get information per Azure DevOps organization and project. Each project may host multiple repositories and Azure Pipelines. So depending on your project setup this part of the solution might need to be adapted to identify the actual build jobs that can be handled by the agents deployed in the cluster.
az pipelines build list --organization 'https://dev.azure.com/anoff' --project 'AKS build test' --status=notStarted|inProgress -o json
- 📌 NOTE
You can only use one of the
statusvalues per request To get allactive jobsyou need to run the command twice and add both numbers.
Scaling to the correct amount of agents
This is the part where things got a little tricky. The provided Cluster Autoscaler for AKS only takes care of scaling underlying resources. To allow resources to scale we need to remove/add build agent pods based on the active jobs. When there are more jobs than pod it should be rather easy to add more pods to the cluster. However when there are more pods (build agents) than there are active build jobs the solution needs to scale down. While some build agents are actively running jobs this is a stateful scenario where we want to identify exactly which pod should be taken down because its corresponding build agent is currently not actively running a build job.
Kubernetes becomes extremely complicated if your solution is not stateless
In this scenario stateless means that we can treat all build agents the same. This is only true at a point where there are no active jobs in the system. But that point is also when all agents can be removed completely. Without an additional scale-down solution that would mean the cluster increasing in size and only scaling down once no builds are running. While this may work over a larger time window it was a too big trade-off for me to already be satisfied with it.
The solution to this problem was combining the configuration options that the Azure Pipelines agent brings with the type of workloads that Kubernetes can run.
My initial approach was to run StatefulSet in Kubernetes that allow running pods with mounted volumes (see requirements).
However using the Batch Jobs API of Kubernetes it is possible to spawn pods that only run until the process inside the pod ends.
Luckily there is a --once flag when staring an Azure Pipelines agent that terminates the agent after one job has been handled.
This means that the number of active jobs just needs to be identical to the number of Batch Jobs inside the AKS cluster.
After the build jobs are done the pod is automatically removed from the cluster and the Cluster Autoscaler will take care of removing the underlying hardware (VMSS) after it has been idling long enough.
This scale-down scenario is really nice because it requires no state handling from the outside regarding the lifecycle of individual agents.
Instead all agents share an identical, ephemeral, short lifecycle:
All agents are treated the same; they start, they run a single job, they stop, they get terminated.
Pipeline agent lifecycle
To trigger the creation of new pipeline agents via the kubernets BatchJob API I wrote a small python script that identifies the number of active jobs and compares it with the number of agent pods running in AKS.
For any additional job a new BatchJob is started via Helm.
The script itself is running inside Kubernetes in a CronJob that gets executed once per minute.
Kubernetes setup
Putting it all together
All parts of the puzzle seemed to be solved. The above sections describe how to
- host a dockerized Azure Pipelines agent
- identify how many agents are needed
- automatically scale the underlying infrastructure (= cost)
- deal with the lifecycle problem of the agents
In addition all initial requirements are fulfilled. The solution I cam up with is pictured below
Overview of the solution
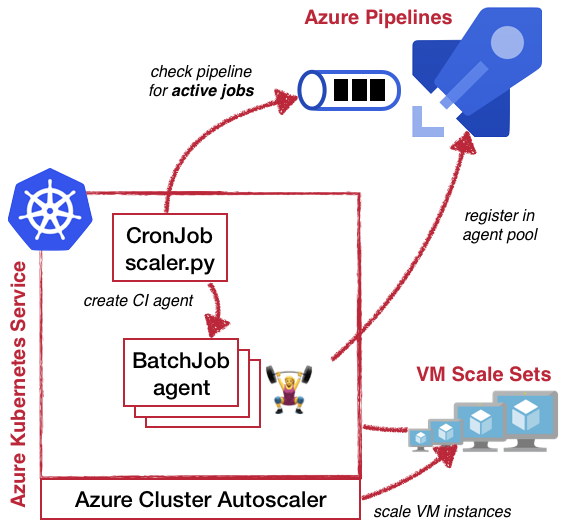
In a follow up blog post I will provide some implementation details. If you are interested in any specific parts please leave a comment or contact me via Twitter 👋